Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : Framablog
Les technologies qui permettent la décentralisation du Web suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous permettent d’échapper aux silos propriétaires qui collectent et monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et autres ressources qui reposent sur le protocole activityPub. Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt ?
Aujourd’hui nous vous proposons la traduction d’un bref article introducteur à une technologie qui permet de produire et héberger son site web sur son ordinateur et de le diffuser sans le moindre serveur depuis un navigateur.
L’article original est issu de la série Dweb (Decentralized Web) publiée sur Mozilla Hacks, dans laquelle Dietrich Ayala met le projecteur sur toutes les initiatives récentes autour du Web décentralisé ou distribué.
Traduction Framalang : bengo35, goofy
 Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.
Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.

L’équipe Blue Link Labs
Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place.
Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? »
Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web !
Beaker utilise un réseau pair-à-pair distribué pour publier des sites web et des jeux de données (parfois nous appelons ça des « dats »).
Les sites web dat:// sont joignables avec une clé publique faisant office d’URL, et chaque donnée ajoutée à un site web dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce à une table de hachage distribuée1, puis ils synchronisent les données entre eux, agissant à la fois comme téléchargeurs et téléverseurs, et vérifiant que les données n’ont pas été altérées pendant le transit.
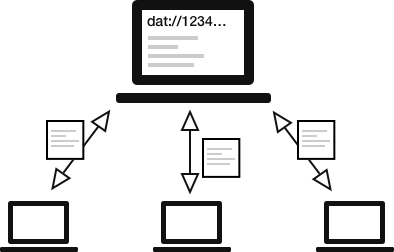
Une illustration basique du réseau dat://
Techniquement, un site Web dat:// n’est pas tellement différent d’un site web https:// . C’est une collection de fichiers et de dossiers qu’un navigateur Internet va interpréter suivant les standards du Web. Mais les sites web dat:// sont spéciaux avec Beaker parce que nous avons ajouté une API (interface de programmation) qui permet aux développeurs de faire des choses comme lire, écrire, regarder des fichiers dat:// et construire des applications web pair-à-pair.
Beaker rend facile pour quiconque de créer un nouveau site web dat:// en un clic (faire le tour des fonctionnalités). Si vous êtes familier avec le HTML, les CSS ou le JavaScript (même juste un peu !) alors vous êtes prêt⋅e à publier votre premier site Web dat://.
Les développeurs peuvent commencer par regarder la documentation de notre interface de programmation ou parcourir nos guides.
L’exemple ci-dessous montre comment fabriquer le site Web lui-même via la création et la sauvegarde d’un fichier JSON. Cet exemple est fictif mais fournit un modèle commun pour stocker des données, des profils utilisateurs, etc. pour un site Web dat:// : au lieu d’envoyer les données de l’application sur un serveur, elles peuvent être stockées sur le site web lui-même !
// index.html
Submit message
<script src="index.js"></script>
// index.js
// first get an instance of the website's files
var files = new DatArchive(window.location)
document.getElementById('create-json-button').addEventListener('click', saveMessage)
async function saveMessage () {
var timestamp = Date.now()
var filename = timestamp + '.json'
var content = {
timestamp,
message : document.getElementById('message').value
}
// write the message to a JSON file
// this file can be read later using the DatArchive.readFile API
await files.writeFile(filename, JSON.stringify(content))
}
Nous avons hâte de voir ce que les gens peuvent faire de dat:// et de Beaker. Nous apprécions tout spécialement quand quelqu’un crée un site web personnel ou un blog, ou encore quand on expérimente l’interface de programmation pour créer une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
dat://12420d10773ccc076898b7d782263cde666112b74dff6d4e1eabf2e4bfcdb672/Documentation plus technique
À propos de Tara Vancil
Tara est la co-créatrice du navigateur Beaker. Elle a travaillé précédemment chez Cloudflare et participé au Recurse Center.
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Bien qu’il ne puisse pas dire avec certitude ce qui explique la différence, Gerstein soupçonne que cela doit provenir des algorithmes que chaque entreprise utilise pour obtenir les données génétiques. […] « La façon dont ces calculs sont effectués est différente. » Lorsqu’on leur a demandé pourquoi les jumelles n’avaient pas obtenu les mêmes résultats alors que leur ADN est si similaire, 23andMe a dit à Marketplace dans un courriel que même ces variations mineures peuvent amener son algorithme à attribuer des estimations légèrement différentes de l’ascendance. L’entreprise a déclaré qu’elle aborde le développement de ses outils et rapports avec rigueur scientifique, mais admet que ses résultats sont des « estimations statistiques ».
Schufa est une agence d’évaluation du crédit qui génère des scores financiers pour les emprunteurs potentiels en Allemagne à peu près équivalent aux scores FICO aux États-Unis. L’algorithme de Schufa n’est pas ouvert, et par conséquent, des décisions financières importantes sont médiées par un processus inconnu qui peut être assez capricieux dans sa notation. […] les activistes ont appris que l’algorithme pouvait être très « sujet aux erreurs » – créant des scores relativement négatifs sans aucune raison négative. La publication de ces résultats a poussé les régulateurs à plaider en faveur d’une plus grande transparence sur les scores de crédit en Allemagne, et a également conduit Schufa à commencer à proposer leurs informations sous forme numérique, plutôt que papier.


« Évangéliser ». C’est le terme, très significatif, employé chez Microsoft pour désigner les actions visant à diffuser le plus largement possible la culture numérique dans la population… et au passage, ramener dans le troupeau du géant de Redmond les brebis qui risqueraient de s’égarer du côté de la concurrence ou, pire, de se tourner vers les logiciels libres. L’inattendu, c’est que, en France, les missionnaires de la multinationale reçoivent l’aval et même l’appui du ministère de l’Éducation nationale, pourtant garant d’un principe de laïcité qui implique de préserver aussi les élèves de la propagande commerciale.


Cela parait délirant mais c’est pourtant tout à fait logique de considérer cette destruction comme plus rentable. Cette situation vous choque toujours ? Et bien c’est la norme dans toute la grande distribution. Amazon est ici pointé du doigt mais ce scénario se répète tous les jours dans tous les systèmes de distribution de masse. Les supermarchés et hypermarchés évidemment mais même les boutiques de vente en aéroport ou dans les gares jettent des milliers d’invendus chaque jour.
Les rares produits “sauvés” ne le sont que par les hard discounters. Cela survient quand le stock de produits est important et que les marchands comprennent que celui qui vous propose une misère pour racheter un lot à perte reste de toutes façons plus intéressant que de devoir payer pour détruire des produits après les avoir stockés pendant des semaines. Dans la grande majorité des cas, tout le monde détruit.

Dans l’optique de pouvoir utiliser efficacement l’intelligence artificielle, l’humain aligne – au début consciemment et ensuite plus inconsciemment – son comportement (et aussi sa pensée) sur le modèle plus standard de l’IA. C’est un humain qui se robotise par anticipation. […] Ce nivellement par le bas (technomimétique) de l’humain n’est pas sans effet. D’une manière générale, en se robotisant, il finit forcément par se déshumaniser. D’une manière précise, il profite du développement de l’IA sur le plan de l’utilité, de l’efficacité, et du rendement, tout en perdant jusqu’à un certain degré des éléments qui le composent dans ce qui fait de lui un être à proprement parler imparfait, et donc pas un robot.
[…] Prenons l’exemple de l’oubli. C’est un de ces éléments qui nous caractérisent depuis toujours, que cela nous plaise ou non. Néanmoins, à l’heure de l’IA et du numérique, on oublie jusqu’à l’existence de cette lacune. On pourrait dire que l’humain oublie l’oubli. Aujourd’hui, tout est sauvegardé dans des bases de données et la mémoire devient du coup matérielle, à savoir qu’il devient (presque) impossible d’oublier.
Entre 1970 et 1973, sous le gouvernement de Salvador Allende au Chili est né le projet Cybersyn. Ce fut une idée d’organisation cybernétique de gouvernement, une sorte de procédé semi-automatique d’organisation économique et politique… un outil surprenant et esthétiquement peu éloigné des épisodes de Star Trek. On l’a aussi accusé d’être une tentative de contrôle des individus, mais sa courte vie ne permet pas vraiment de l’affirmer.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Et un grand merci à Goofy, toujours là pour donner un coup de patte en cas de besoin ! ! !
Alors que se répandent les enceintes connectées (comme le Google Home ou l’Amazon Echo), fleurissent aussi des projets pour les empêcher de vous écouter en permanence (ce qui est nécessaire à leur fonctionnement normal, rappelons-le).
Cela peut faire sourire car le meilleur moyen de ne pas être espionné par ce genre d’objet, c’est encore de s’en passer. La question qui se pose alors, c’est : doit-on accepter d’aller chez des gens qui ont ce genre d’objet chez eux ?

Crédit : Simon Gee Giraudot (Creative Commons By-Sa)
Nous avons souhaité partager avec vous ce texte, mi-fiction mi réflexion, de Neil Jomunsi. Et nous l’avons même invité à en publier d’autres ici s’il le souhaite. Bonne lecture.
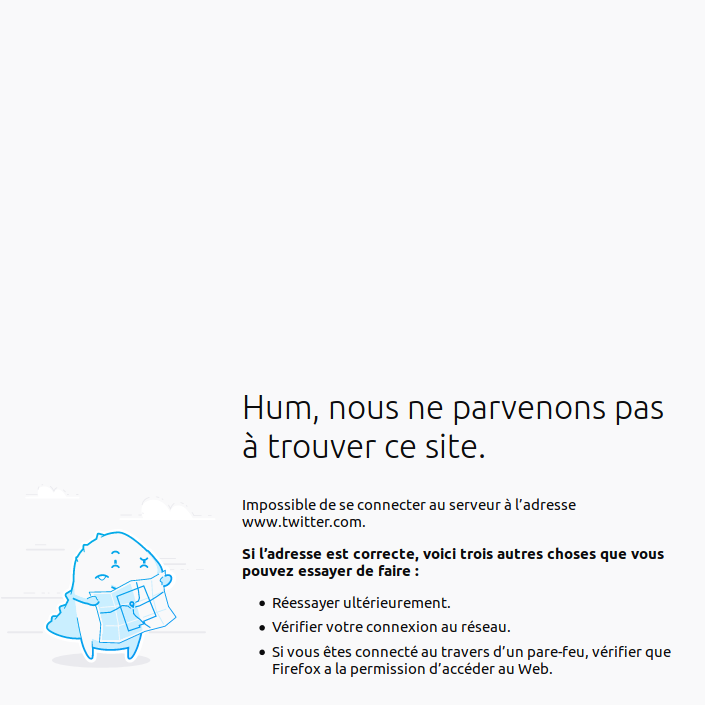
C’était inéluctable, nous le savions, parce que rien en ce monde n’est éternel, mais nous ne pouvions pas nous empêcher d’espérer. On a beaucoup parlé, évoqué un temps un possible rachat collectif par tous les utilisateurs, mais le monde étant devenu complexe, il ne se satisfait plus de réponses simpl(ist)es. Ce jour du 29 avril 2026 est donc à marquer d’une pierre blanche : deux ans après Facebook, dont la fermeture de la branche « réseau social » avait provoqué le tollé que l’on sait, Twitter a officiellement annoncé qu’il fermait à son tour les portes de son service. Le bureau d’administration a tranché : plus assez rentable. Twitter venait tout juste de fêter son vingtième anniversaire.
Twitter avait pourtant connu une embellie dans le courant 2020, profitant de la démocratisation des technologies de contrôle vocal et d’intelligence artificielle, et offrant à ses utilisateurs des interfaces toujours plus personnalisées, à mi-chemin entre salon de discussion public et messagerie privée. Les critiques n’avaient pas été tendres lorsque le service de micro-blogging avait décidé de renforcer la part algorithmique des messages affichés aux utilisateurs, mais la tempête avait fini par passer ; car les utilisateurs ont fini, on le sait, par adhérer au concept de bulle de filtres, la vague du « webcare » étant passée par-là, popularisée par des livres de développement personnel tels que Le miroir du réseau ou Modelez le web à votre image.
Bien sûr, les défenseurs d’un web libre et décentralisé avaient prévenu : avec la concentration des données sur une poignée de grosses plateformes, c’était tout un pan de la réflexion et de la création du XXIe qui courait le risque de disparaître purement et simplement de l’histoire. Ils n’ont pas été démentis : avec Twitter qui ferme, ce sont 20 années d’échanges, de contradictions, de propos calomnieux, injurieux ou mensongers aussi, qui sombrent dans le néant. Twitter assure que les usagers pourront télécharger leur archive personnelle pendant encore un an à compter de la date de fermeture officielle, qui devrait être annoncée sous peu. Mais sans la connexion entre les différents comptes qui rendait lesdites archives dynamiques, et donc pertinentes, ces sauvegardes risquent fort de perdre tout intérêt documentaire pour les historiens. D’autant que peu d’internautes décideront d’en faire quelque chose, et la plupart finiront par pourrir dans un coin de cloud oublié.
Soixante-seize chercheurs et historiens ont publié lundi dans Le Monde une tribune invitant les états à se saisir du dossier et à négocier avec Twitter une pérennisation de la disponibilité en ligne du service, dans un souci de conservation. Il ne s’agirait pas de permettre aux utilisateurs de continuer à utiliser le service, mais de le garder en ligne en l’état, consultable librement par tous. On le sait, Twitter a été le lieu de toutes les discussions politiques des dix dernières années. Avec sa disparition, craignent les signataires, on risque de voir se créer « le plus grand trou noir de l’histoire moderne », comparable avec celui de la disparition des œuvres hors domaine public en déficit d’exploitation.
Alors bien sûr, tout ceci est une fiction.
Mais Twitter fermera ses portes un jour, vous pouvez en être assurés. Et il y a de bonnes chances pour que les choses se déroulent de cette façon. On l’aura encore vu avec Tumblr récemment : faire confiance à de grandes entreprises multinationales pour conserver notre patrimoine artistique, historique et politique est une grave erreur. Nous devons reprendre le contrôle sur nos publications, et a minima les héberger nous-mêmes, sur un blog sur lequel nous avons tout contrôle.
Sans quoi les mites troueront bientôt – et plus vite qu’on ne l’imagine – le tissu de notre mémoire collective.
—
Lire sur le site originel : https://page42.org/mauvaise-nouvelle-twitter-va-fermer/
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
L’article 13 s’applique aux plateformes Internet qui organisent et promeuvent de grandes quantités d’œuvres protégées par le droit d’auteur téléchargées par leurs utilisateurs dans le but de réaliser un profit.
Notez que « protégé par le droit d’auteur » ne signifie pas « violant le droit d’auteur » ! Tous les textes créatifs, photos, vidéos, etc. sont automatiquement protégés par le droit d’auteur, donc ceci s’applique à toutes les plateformes où les utilisateurs s’expriment, comme Facebook, Instagram, Tumblr, TikTok, Twitch, Wattpad, Imgur, Giphy, etc.
Ces plateformes sont responsables des violations du droit d’auteur commises par leurs utilisateurs.
Il s’agit de la disposition essentielle : légalement, tout ce que nous publions sur les plateformes sera traité comme si les employés de la plateforme l’avaient téléchargé eux-mêmes. Si un seul utilisateur commet une infraction au droit d’auteur, ce sera comme si la plateforme l’avait fait elle-même. Cela obligera les plateformes à prendre des mesures drastiques, puisqu’elles ne pourront jamais dire avec certitude lesquels de nos messages ou téléchargements les exposeront à une responsabilité coûteuse. Il se peut que cela les contraigne à restreindre le nombre de personnes autorisées à publier/télécharger du contenu, d’exiger une identification personnelle des personnes téléchargeant et/ou de bloquer la plupart des téléchargements à l’aide de filtres extrêmement stricts pour ne pas courir de risques.[…] Le texte final de l’article 13 obligera les plateformes Internet, sur lesquelles nous comptons tous pour nous exprimer en ligne, à installer des filtres de téléchargement et/ou à restreindre notre capacité à publier et partager des contenus. On ne peut pas laisser faire ça. Vos représentants élus au Parlement européen auront une dernière chance de rejeter l’article 13 lorsqu’il sera soumis au vote final juste avant les prochaines élections européennes. Préparez-vous à prendre contact avec vos eurodéputés !
Voir à ce propos le travail effectué par la Quadrature… Et on pense à les soutenir !


En France, fibrer les campagnes n’est pas une mince affaire et les opérateurs commerciaux rechignent généralement à investir sur des secteurs coûteux et finalement assez peu peuplés. Pour pallier le problème,le gouvernement a mis en place un mécanisme introduit en 2013 baptisé RIP, pour Réseau d’Initiative Publique, afin de raccorder au réseau fibre les zones moins denses et rurales. Ce mécanisme doit permettre à une collectivité locale de déployer son propre réseau fibre, soit en passant par une relégation de service avec un acteur commercial, un partenariat public privé ou bien le déploiement du réseau en propre.
Pour de nombreux petits acteurs associatifs et FAI, ces RIP constituent un point d’entrée sur le marché de la fibre qui était jusque là la chasse gardée des gros opérateurs disposant de la capacité d’investissement suffisante déployer le réseau fibre. En l’absence de capacité d’investissement suffisante, les petits acteurs ne peuvent compter que sur la mise en place « d’offre active », terme qui désigne le fait de proposer une mutualisation du réseau fibre. En d’autres termes : il s’agit pour le RIP de louer l’accès à son réseau fibre à d’autres acteurs afin de leur permettre de proposer leurs services en très haut débit. […] Sur [l]e site [du Baromètre FTTH], les bénévoles de FFDN publient les informations qu’ils sont parvenus à obtenir sur les conditions d’accès aux différents RIP déployés en France. On y retrouve le type de contrat mis en place (délégation de service public, partenariat public privé et autres dispositions de ce type), une évaluation des prix pratiqués par abonné ou pour se connecter au réseau et d’autres critères détaillés par la fédération dans leur méthodologie. Ces différents aspects sont synthétisés sur une note allant de A à D, avec une note additionnelle Z utilisée pour distinguer les plus mauvais élèves.
Ces jeux vidéo multijoueurs, écrit le ministère des armées dans l’offre de stage, sont « détournés de leur utilisation première » : « les moyens de communication mis à disposition dans ces jeux sont utilisés de manière furtive afin d’échanger de l’information spécifique. »
Trois missions incomberont au stagiaire : d’abord, « effectuer une cartographie » des principaux jeux multijoueurs, et notamment identifier des failles informatiques déjà découvertes. Ensuite, de sélectionner un ou deux jeux particulièrement intéressants pour le service et de l’étudier, afin « d’extraire des signatures réseau », c’est-à-dire des éléments techniques permettant à la DGSE de reconnaître, dans la masse de données dont elle dispose et qu’elle collecte sur Internet, les échanges effectués dans l’espace de discussion du ou des jeux en question. Enfin, le stagiaire devra tenter de découvrir des failles informatiques, censées permettre à la DGSE d’accéder au contenu des discussions.

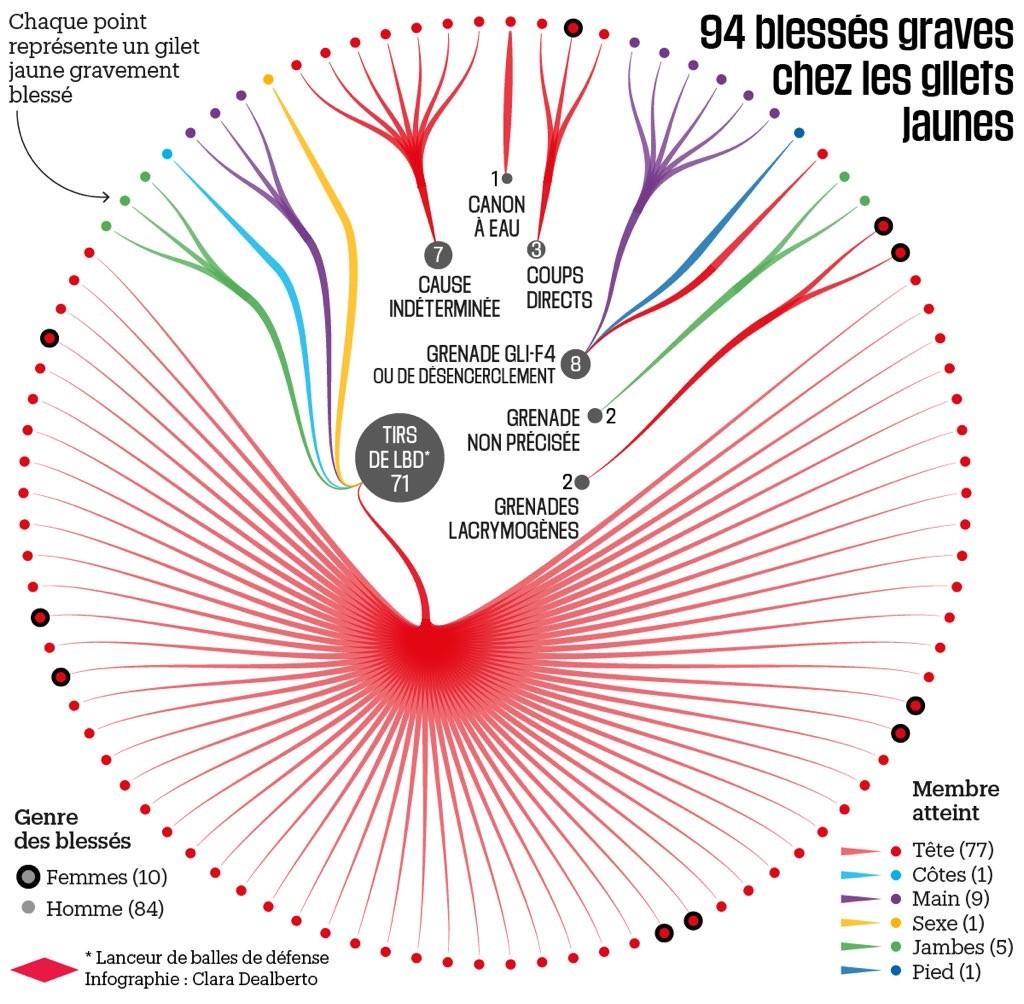
« Quand j’ai débuté le recensement des violences policières sur Twitter, je souhaitais simplement comprendre ce qui se passait. […] Jamais je n’aurais pu imaginer une telle masse de blessés, de non-respect des règles les plus basiques du maintien de l’ordre, de provocations. Ce qui se passe est absolument ahurissant pour quelqu’un qui a travaillé sur le maintien de l’ordre français et connaît son histoire. Des manquements graves à une telle échelle, c’est inouï. Même si la police des polices menait de véritables enquêtes, ce ne serait pas suffisant : il y a un véritable mouvement de fond.
Avant tout, je veux savoir pourquoi il y a eu tous ces blessés et mutilés. Pourquoi on traîne une dame par les cheveux sur quarante mètres. Pourquoi on tire au flash-ball en pleine figure. Pourquoi on éborgne des gens qui ne faisaient que manifester. Pourquoi ces terribles images de gamins matés à Mantes-la-Jolie, sans que cela n’émeuve véritablement au-delà d’un tweet indigné. Je suis tout bonnement sidéré par ces images et ces témoignages. Sachant qu’il n’y a jamais aucune innocence en matière de maintien de l’ordre : c’est un domaine éminemment politique, assujetti au pouvoir. »

En octobre 2001, un mois après les attentats du 11 septembre, Daniel Vaillant, un socialiste, alors ministre de l’Intérieur sous le gouvernement Jospin, a proposé un ensemble de mesures pour lutter contre le terrorisme. La première d’entre elles est la disposition 78-2-2. Cet article du code de procédure pénale permet au procureur de la République d’autoriser les policiers à contrôler les identités des personnes qui se situent dans une zone et une période données, sans avoir à justifier d’aucune raison. Ces policiers peuvent aussi procéder à la visite des véhicules et à la fouille des bagages — en temps normal, un policier ne peut vous contrôler dans la rue que s’il vous reproche une infraction. 17 ans après, ce même article est utilisé contre des personnes souhaitant se rendre à l’une des manifestations des gilets jaunes.[…] Cette histoire est d’autant plus grave que Daniel Vaillant avait alors justifié cet article à l’Assemblée nationale en disant en substance : « Nous sommes dans un moment exceptionnel, juste après les attentats, il faut se protéger du terrorisme. Je vous propose donc cette mesure, en la limitant dans le temps et dans sa matérialité. » La mesure était limitée à deux ans, jusqu’au 31 décembre 2003 ; Sarkozy, au pouvoir, décidera de la rendre pérenne. Vaillant parlait de limitation dans le temps mais aussi dans le champ d’application de cette mesure — aux actes de terrorisme, aux trafics de drogue et d’armes (car considérés comme finançant le terrorisme) ; Sarkozy l’a étendue aux vols et recels. Aujourd’hui, elle est utilisée pour des infractions de droit commun.
Fondamentalement, Hoffman-Andrews considère les problèmes de confidentialité des enceintes intelligentes comme une question de consentement, tant pour les propriétaires des appareils que pour les personnes qui les entourent. Vos colocataires ont-ils accepté que leurs voix soient enregistrées et accessibles plus tard sur votre compte Amazon ? Et vos invités ? La question se complique encore plus pour les enfants. Si vous entrez dans la maison de quelqu’un et qu’il a un de ces appareils, il n’est pas vraiment socialement acceptable de dire : « En fait, je ne vais pas entrer parce que je ne veux pas être dans une maison avec ça », […] « Alors on doit se soumettre à ce qu’on peut considérer comme une surveillance. »
Il craint également que la surveillance ne devienne plus littérale. Si l’on pouvait faire en sorte que les haut-parleurs intelligents s’activent sans qu’il n’y ait de « mot de réveil », selon lui, ils pourraient être utilisés par les forces de l’ordre ou les services de renseignement pour surveiller des cibles comme des militants, des journalistes ou des personnes faisant l’objet d’une enquête criminelle.

Je fais souvent référence à Facebook comme à « l’ami des arnaqueurs ». C’est le premier endroit où je vais quand j’essaie de cibler quelqu’un. Des photos de leur famille, de leur domicile, de leur école et de leur lieu de travail, leurs habitudes de voyage, leurs amis et leurs réponses aux questions de sécurité sont souvent disponibles. La quantité de renseignements personnels que les gens donnent volontiers à Mark Zuckerberg & Co est aussi étonnante qu’imprudente. Si vous ne me croyez pas, vous n’avez qu’à télécharger une copie de vos données – cela ne prend que trois clics et pour la plupart des utilisateurs, c’est suffisant pour changer leurs habitudes de médias sociaux. Vous voyez, sur Facebook, même les utilisateurs avertis qui ont vérifié tous leurs paramètres de sécurité sont aussi sûrs que leur ami le moins sûr. Peu importe à quel point votre compte est verrouillé, si quelqu’un aime votre photo de profil, je peux voir son nom et trouver son compte. Ils ont peut-être des photos de votre mariage ou de vos dernières vacances ? Peut-être que cette demande d’amitié d’un collègue disparu depuis longtemps, c’est en fait moi, caché derrière une photo volée ?
Le mythe du robot, qui est celui de l’automation complète, qui hante l’imaginaire industriel, d’abord occidental et aujourd’hui global, depuis trois siècles, est une promesse toujours renouvelée, un mirage qui s’éloigne en permanence… C’est un horizon utopique, mais qui a un impact très concret sur la vie de tous les jours. Parce que depuis des siècles, ce mythe est utilisé pour discipliner la force de travail, obliger les travailleurs à se tenir à carreau parce qu’on peut toujours les remplacer par une machine à vapeur, puis une machine industrielle, et maintenant une machine intelligente. Le robot dont on parle n’est pas un automate anthropomorphe, c’est aujourd’hui un robot de données, c’est-à-dire une manière d’automatiser les processus métier. Et cette automatisation passe aujourd’hui par ce qu’on appelle intelligence artificielle, laquelle est fondée sur la présence de données. Mais quand on dit ça, on oublie toujours de dire qui produit ces données. Elles sont produites par les mêmes personnes qui connaissent le risque d’être éjectées de l’emploi formel. Parce qu’on a besoin de quelqu’un qui tague les images, qui trie les données, qui nettoie l’information, et ce quelqu’un, ce n’est pas un ingénieur ou un « data scientist », ce sont vous et nous, et des centaines de millions de personnes, entre les Philippines et la Côte-d’Ivoire, qui, à longueur de journée, doivent produire ces données qui sont indispensables à l’apprentissage statistique et à l’économie des robots.


Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}