Mise à jour
Mise à jour de la base de données, veuillez patienter...
Site original : Framablog
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
L’article 13 s’applique aux plateformes Internet qui organisent et promeuvent de grandes quantités d’œuvres protégées par le droit d’auteur téléchargées par leurs utilisateurs dans le but de réaliser un profit.
Notez que « protégé par le droit d’auteur » ne signifie pas « violant le droit d’auteur » ! Tous les textes créatifs, photos, vidéos, etc. sont automatiquement protégés par le droit d’auteur, donc ceci s’applique à toutes les plateformes où les utilisateurs s’expriment, comme Facebook, Instagram, Tumblr, TikTok, Twitch, Wattpad, Imgur, Giphy, etc.
Ces plateformes sont responsables des violations du droit d’auteur commises par leurs utilisateurs.
Il s’agit de la disposition essentielle : légalement, tout ce que nous publions sur les plateformes sera traité comme si les employés de la plateforme l’avaient téléchargé eux-mêmes. Si un seul utilisateur commet une infraction au droit d’auteur, ce sera comme si la plateforme l’avait fait elle-même. Cela obligera les plateformes à prendre des mesures drastiques, puisqu’elles ne pourront jamais dire avec certitude lesquels de nos messages ou téléchargements les exposeront à une responsabilité coûteuse. Il se peut que cela les contraigne à restreindre le nombre de personnes autorisées à publier/télécharger du contenu, d’exiger une identification personnelle des personnes téléchargeant et/ou de bloquer la plupart des téléchargements à l’aide de filtres extrêmement stricts pour ne pas courir de risques.[…] Le texte final de l’article 13 obligera les plateformes Internet, sur lesquelles nous comptons tous pour nous exprimer en ligne, à installer des filtres de téléchargement et/ou à restreindre notre capacité à publier et partager des contenus. On ne peut pas laisser faire ça. Vos représentants élus au Parlement européen auront une dernière chance de rejeter l’article 13 lorsqu’il sera soumis au vote final juste avant les prochaines élections européennes. Préparez-vous à prendre contact avec vos eurodéputés !
Voir à ce propos le travail effectué par la Quadrature… Et on pense à les soutenir !


En France, fibrer les campagnes n’est pas une mince affaire et les opérateurs commerciaux rechignent généralement à investir sur des secteurs coûteux et finalement assez peu peuplés. Pour pallier le problème,le gouvernement a mis en place un mécanisme introduit en 2013 baptisé RIP, pour Réseau d’Initiative Publique, afin de raccorder au réseau fibre les zones moins denses et rurales. Ce mécanisme doit permettre à une collectivité locale de déployer son propre réseau fibre, soit en passant par une relégation de service avec un acteur commercial, un partenariat public privé ou bien le déploiement du réseau en propre.
Pour de nombreux petits acteurs associatifs et FAI, ces RIP constituent un point d’entrée sur le marché de la fibre qui était jusque là la chasse gardée des gros opérateurs disposant de la capacité d’investissement suffisante déployer le réseau fibre. En l’absence de capacité d’investissement suffisante, les petits acteurs ne peuvent compter que sur la mise en place « d’offre active », terme qui désigne le fait de proposer une mutualisation du réseau fibre. En d’autres termes : il s’agit pour le RIP de louer l’accès à son réseau fibre à d’autres acteurs afin de leur permettre de proposer leurs services en très haut débit. […] Sur [l]e site [du Baromètre FTTH], les bénévoles de FFDN publient les informations qu’ils sont parvenus à obtenir sur les conditions d’accès aux différents RIP déployés en France. On y retrouve le type de contrat mis en place (délégation de service public, partenariat public privé et autres dispositions de ce type), une évaluation des prix pratiqués par abonné ou pour se connecter au réseau et d’autres critères détaillés par la fédération dans leur méthodologie. Ces différents aspects sont synthétisés sur une note allant de A à D, avec une note additionnelle Z utilisée pour distinguer les plus mauvais élèves.
Ces jeux vidéo multijoueurs, écrit le ministère des armées dans l’offre de stage, sont « détournés de leur utilisation première » : « les moyens de communication mis à disposition dans ces jeux sont utilisés de manière furtive afin d’échanger de l’information spécifique. »
Trois missions incomberont au stagiaire : d’abord, « effectuer une cartographie » des principaux jeux multijoueurs, et notamment identifier des failles informatiques déjà découvertes. Ensuite, de sélectionner un ou deux jeux particulièrement intéressants pour le service et de l’étudier, afin « d’extraire des signatures réseau », c’est-à-dire des éléments techniques permettant à la DGSE de reconnaître, dans la masse de données dont elle dispose et qu’elle collecte sur Internet, les échanges effectués dans l’espace de discussion du ou des jeux en question. Enfin, le stagiaire devra tenter de découvrir des failles informatiques, censées permettre à la DGSE d’accéder au contenu des discussions.

« Quand j’ai débuté le recensement des violences policières sur Twitter, je souhaitais simplement comprendre ce qui se passait. […] Jamais je n’aurais pu imaginer une telle masse de blessés, de non-respect des règles les plus basiques du maintien de l’ordre, de provocations. Ce qui se passe est absolument ahurissant pour quelqu’un qui a travaillé sur le maintien de l’ordre français et connaît son histoire. Des manquements graves à une telle échelle, c’est inouï. Même si la police des polices menait de véritables enquêtes, ce ne serait pas suffisant : il y a un véritable mouvement de fond.
Avant tout, je veux savoir pourquoi il y a eu tous ces blessés et mutilés. Pourquoi on traîne une dame par les cheveux sur quarante mètres. Pourquoi on tire au flash-ball en pleine figure. Pourquoi on éborgne des gens qui ne faisaient que manifester. Pourquoi ces terribles images de gamins matés à Mantes-la-Jolie, sans que cela n’émeuve véritablement au-delà d’un tweet indigné. Je suis tout bonnement sidéré par ces images et ces témoignages. Sachant qu’il n’y a jamais aucune innocence en matière de maintien de l’ordre : c’est un domaine éminemment politique, assujetti au pouvoir. »

En octobre 2001, un mois après les attentats du 11 septembre, Daniel Vaillant, un socialiste, alors ministre de l’Intérieur sous le gouvernement Jospin, a proposé un ensemble de mesures pour lutter contre le terrorisme. La première d’entre elles est la disposition 78-2-2. Cet article du code de procédure pénale permet au procureur de la République d’autoriser les policiers à contrôler les identités des personnes qui se situent dans une zone et une période données, sans avoir à justifier d’aucune raison. Ces policiers peuvent aussi procéder à la visite des véhicules et à la fouille des bagages — en temps normal, un policier ne peut vous contrôler dans la rue que s’il vous reproche une infraction. 17 ans après, ce même article est utilisé contre des personnes souhaitant se rendre à l’une des manifestations des gilets jaunes.[…] Cette histoire est d’autant plus grave que Daniel Vaillant avait alors justifié cet article à l’Assemblée nationale en disant en substance : « Nous sommes dans un moment exceptionnel, juste après les attentats, il faut se protéger du terrorisme. Je vous propose donc cette mesure, en la limitant dans le temps et dans sa matérialité. » La mesure était limitée à deux ans, jusqu’au 31 décembre 2003 ; Sarkozy, au pouvoir, décidera de la rendre pérenne. Vaillant parlait de limitation dans le temps mais aussi dans le champ d’application de cette mesure — aux actes de terrorisme, aux trafics de drogue et d’armes (car considérés comme finançant le terrorisme) ; Sarkozy l’a étendue aux vols et recels. Aujourd’hui, elle est utilisée pour des infractions de droit commun.
Fondamentalement, Hoffman-Andrews considère les problèmes de confidentialité des enceintes intelligentes comme une question de consentement, tant pour les propriétaires des appareils que pour les personnes qui les entourent. Vos colocataires ont-ils accepté que leurs voix soient enregistrées et accessibles plus tard sur votre compte Amazon ? Et vos invités ? La question se complique encore plus pour les enfants. Si vous entrez dans la maison de quelqu’un et qu’il a un de ces appareils, il n’est pas vraiment socialement acceptable de dire : « En fait, je ne vais pas entrer parce que je ne veux pas être dans une maison avec ça », […] « Alors on doit se soumettre à ce qu’on peut considérer comme une surveillance. »
Il craint également que la surveillance ne devienne plus littérale. Si l’on pouvait faire en sorte que les haut-parleurs intelligents s’activent sans qu’il n’y ait de « mot de réveil », selon lui, ils pourraient être utilisés par les forces de l’ordre ou les services de renseignement pour surveiller des cibles comme des militants, des journalistes ou des personnes faisant l’objet d’une enquête criminelle.

Je fais souvent référence à Facebook comme à « l’ami des arnaqueurs ». C’est le premier endroit où je vais quand j’essaie de cibler quelqu’un. Des photos de leur famille, de leur domicile, de leur école et de leur lieu de travail, leurs habitudes de voyage, leurs amis et leurs réponses aux questions de sécurité sont souvent disponibles. La quantité de renseignements personnels que les gens donnent volontiers à Mark Zuckerberg & Co est aussi étonnante qu’imprudente. Si vous ne me croyez pas, vous n’avez qu’à télécharger une copie de vos données – cela ne prend que trois clics et pour la plupart des utilisateurs, c’est suffisant pour changer leurs habitudes de médias sociaux. Vous voyez, sur Facebook, même les utilisateurs avertis qui ont vérifié tous leurs paramètres de sécurité sont aussi sûrs que leur ami le moins sûr. Peu importe à quel point votre compte est verrouillé, si quelqu’un aime votre photo de profil, je peux voir son nom et trouver son compte. Ils ont peut-être des photos de votre mariage ou de vos dernières vacances ? Peut-être que cette demande d’amitié d’un collègue disparu depuis longtemps, c’est en fait moi, caché derrière une photo volée ?
Le mythe du robot, qui est celui de l’automation complète, qui hante l’imaginaire industriel, d’abord occidental et aujourd’hui global, depuis trois siècles, est une promesse toujours renouvelée, un mirage qui s’éloigne en permanence… C’est un horizon utopique, mais qui a un impact très concret sur la vie de tous les jours. Parce que depuis des siècles, ce mythe est utilisé pour discipliner la force de travail, obliger les travailleurs à se tenir à carreau parce qu’on peut toujours les remplacer par une machine à vapeur, puis une machine industrielle, et maintenant une machine intelligente. Le robot dont on parle n’est pas un automate anthropomorphe, c’est aujourd’hui un robot de données, c’est-à-dire une manière d’automatiser les processus métier. Et cette automatisation passe aujourd’hui par ce qu’on appelle intelligence artificielle, laquelle est fondée sur la présence de données. Mais quand on dit ça, on oublie toujours de dire qui produit ces données. Elles sont produites par les mêmes personnes qui connaissent le risque d’être éjectées de l’emploi formel. Parce qu’on a besoin de quelqu’un qui tague les images, qui trie les données, qui nettoie l’information, et ce quelqu’un, ce n’est pas un ingénieur ou un « data scientist », ce sont vous et nous, et des centaines de millions de personnes, entre les Philippines et la Côte-d’Ivoire, qui, à longueur de journée, doivent produire ces données qui sont indispensables à l’apprentissage statistique et à l’économie des robots.


Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Ces dernières semaines nous avons publié par chapitres successifs notre traduction de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt.
Vous trouverez ci-dessous en un seul document sous deux formats (.odt et .pdf) non seulement l’ensemble des chapitres publiés précédemment mais aussi les copieuses annexes qui référencent les recherches menées par l’équipe ainsi que les éléments qui ne pouvaient être détaillés dans les chapitres précédents.
Traduction Framalang pour l’ensemble du document :
Alain, Barbara, Bullcheat, Côme, David_m, fab, Fabrice, FranBAG, Goofy, jums, Khrys, Mika, Obny, Penguin, Piup, Serici. Remerciements particuliers à Cyrille.
Nous avons fait de notre mieux, mais des imperfections de divers ordres peuvent subsister, n’hésitez pas à vous emparer de la version en .odt pour opérer les rectifications que vous jugerez nécessaires.

.PDF Version 3.2 (2,6 Mo)
.ODT Version 3.2 (3,3 Mo)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
« Je me demande si Pai comprend ou non le fonctionnement du Congrès », a déclaré Pallone à Ars Technica aujourd’hui, en réponse à la déclaration d’Ajit Pai. […] L’abrogation de la neutralité du net a été un désastre pour les consommateurs. Elle ne tient pas compte de la volonté du peuple américain et a donné aux fournisseurs de services Internet la possibilité de contrôler les activités en ligne des gens comme bon leur semble. La nouvelle majorité démocrate s’efforcera de rétablir des règles strictes de neutralité du net à la Chambre des représentants cette année. »
Une croyance commune parmi les experts de l’industrie de la tech est que la Silicon Valley a dominé Internet parce qu’une grande partie du réseau mondial avait été conçue et construite par des Américains.
Aujourd’hui, un nombre croissant de ces experts craignent que les restrictions à l’exportation proposées ne court-circuitent la prééminence des entreprises américaines dans le prochain grand changement qui touchera leur industrie : l’intelligence artificielle.

Des photocopies de papiers d’identité, des numéros de comptes bancaires, des photos, des adresses et des numéros de téléphone personnels… Des milliers de documents confidentiels, appartenant principalement à des responsables politiques, mais aussi à des personnalités du monde des médias et de la culture, ont été publiés en ligne.
Une action en justice, au nom de 17 survivants d’un drame en Méditerranée, a été intentée contre l’Italie auprès de la Cour européenne des droits de l’homme.
Une start-up voudrait qu’une femme donne naissance à un enfant à 250 miles au-dessus de la Terre. Première question : mais pourquoi ?

« la difficulté, c’est de pouvoir traiter les données alors qu’on [leur] supprime des emplois à tour de bras […] Car il n’existe pas de “contrôle fiscal-presse bouton”, comme on pourrait le penser. L’argument selon lequel le tout-numérique rend le contrôle fiscal moins onéreux et plus efficace est faux ».
L’histoire du déclin du numérique français est une tragédie en trois actes. Il y eut d’abord les « 30 honteuses du numérique », où une petite élite arrogante et dénuée de vision stratégique a démantelé notre industrie informatique et électronique grand public. […] Vient ensuite la capitulation vis-à-vis des grands acteurs américains. Ainsi, de nombreux politiques et hauts fonctionnaires français leur ont permis d’intégrer leurs technologies au cœur des prérogatives régaliennes de l’État : défense, renseignement, éducation, sécurité, mais aussi culture. Plusieurs d’entre eux quitteront leurs fonctions pour aller rejoindre ces sociétés. Le troisième acte se joue en ce moment. […] Nous aurions pu avoir un autre destin, car si les États-Unis avaient la vision et l’argent, c’est en Europe qu’ont été inventées deux des briques fondamentales de l’Internet : Linux et le Web. Mais à la différence du standard GSM, ces dernières ont eu le malheur d’être conçues par des individus talentueux hors des grandes institutions. Snobés chez nous, ces deux projets deviendront le moteur des plateformes numériques américaines et chinoises et l’instrument de leur domination mondiale.
Une nouvelle étape est franchie dans la folie capitaliste de la « Start-Up nation » : Pôle emploi propose aux chômeurs de télécharger une application qui fait payer les utilisateurs pour être repérés par des recruteurs.
Le nombre de médecins scolaires vient de tomber sous la barre des 1 000 : ils sont 976 professionnels en activité pour… 12,5 millions d’élèves. […] En octobre 2017, l’Académie de médecine avait rendu un rapport « sur la situation alarmante de la médecine scolaire en France », faisant état par endroits d’un seul médecin censé prendre en charge 46 000 élèves… Les conséquences de cette pénurie, très concrètes, touchent en premier lieu les enfants de familles défavorisées. Ceux-là mêmes dont les parents connaissent déjà de telles difficultés pour payer la nourriture et un logement qu’ils n’ont ni le temps ni les moyens de faire les démarches pour aller voir un médecin de ville.
Il faudrait un mot pour qualifier un sentiment de joie mêlée de ressentiment quand on passe une journée à bidouiller sur son ordinateur pour arriver à organiser une information qui aurait été si simple à distribuer par l’administration. Joie de parvenir à récupérer une partie importante des données, disséminées dans des fichiers Excel et PDF, à en tirer du sens et à les partager ensuite.
En abandonnant cette mise en représentation impersonnelle de la fonction présidentielle pour un « instantané » plus intime – François Mitterrand dans « sa » bibliothèque, Jacques Chirac ou François Hollande dans « leur » jardin – le portrait officiel suit certes la présidentialisation de la vie politique. Mais surtout, il délaisse la fiction républicaine d’une charge qui transcenderait l’homme qui l’incarne au profit d’une fiction politique d’un homme qui transcenderait la fonction qu’il occupe. Le passage d’une mise en représentation du pouvoir à une présentation de son titulaire, semble donner raison aux républicains les plus radicaux qui, sous la Troisième République, voyaient dans cette photographie une dérive vers une personnalisation de la fonction présidentielle et une personnification du pouvoir.
Les autorités doivent assurer la sécurité de toute personne et veiller à ce que le droit de manifester pacifiquement soit respecté. Elles doivent prendre des mesures légales et proportionnées pour protéger la vie et l’ordre public, en évitant de recourir à une force excessive .
Le port d’équipements de protection contre les gaz lacrymogènes, les flashball ou les grenades de désencerclement ne saurait être assimilé à une intention de commettre des violences, et les personnes arrêtées uniquement pour ce motif doivent être libérées.


Les adolescents issus de familles à faible revenu passent en moyenne huit heures et sept minutes par jour à utiliser des écrans pour se divertir, tandis que leurs pairs issus de familles à revenu plus élevé n’y passent que cinq heures et 42 minutes, selon une étude de Common Sense Media, un organisme sans but lucratif de surveillance des médias.[…] Deux études prenant les origines raciales en compte ont révélé que les enfants blancs étaient beaucoup moins exposés aux écrans que les enfants afro-américains et hispaniques.
Et les parents affirment qu’il y a un fossé technologique grandissant entre les écoles publiques et privées, même au sein d’une même communauté. Alors que l’école privée Waldorf School of the Peninsula, très populaire auprès des dirigeants de la Silicon Valley, évite la plupart des écrans, l’école publique Hillview Middle School, située à proximité, annonce son programme 1:1 iPad.

Au XVIe siècle, les explorateurs portugais furent les premiers Européens à atteindre la Chine. Les commerçants et les missionnaires suivirent, s’installant à Macao sur des terres louées aux dirigeants de la dynastie chinoise Ming. Les Portugais ont appelé les fonctionnaires Ming qu’ils ont rencontrés mandarim, qui vient de menteri en malais et, avant cela, de mantrī en sanskrit, qui signifie « ministre » ou « conseiller ».


Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Le Japon n’est pas le seul pays à en parler sévèrement. Plus tôt cette année, la Chine (le plus grand marché du jeu au monde) a menacé de prendre des mesures concrètes pour protéger la vue des enfants, notamment en réglementant le nombre de jeux en ligne et les nouvelles versions et en limitant le temps de jeu. Cet annonce citait des données de l’Organisation mondiale de la santé suggérant que le pays présente le taux de myopie infantile le plus élevé au monde.
Chaque uniforme est lié au visage d’un enfant donné, et la reconnaissance faciale à l’entrée de l’école déclenche une alerte si ce n’est pas le bon enfant qui le porte.[…] Et avons-nous mentionné que le système pouvait tracer les élèves après l’école ? Lin note que le personnel ne fait que « choisir de ne pas » suivre les enfants en dehors des heures de classe. Il ne faudrait pas grand-chose à un professeur sans scrupules ou à des représentants du gouvernement pour suivre les élèves au-delà des cours et engendrer une enfance particulièrement dystopique.
« Le projet de réglementation nous a été communiqué et nous en ferons une analyse détaillée. Mais à première vue, ils semblent envisager une censure proactive et rompre le chiffrement via la traçabilité. Ils feront d’Internet un environnement portant atteinte aux droits fondamentaux des utilisateurs », a déclaré Apar Gupta, avocat et cofondateur de l’Internet Freedom Foundation. « Toutes ces propositions font l’objet de discussions secrètes sans aucune consultation publique. Je crains que les récentes mesures gouvernementales ne nous rapprochent beaucoup du modèle de censure chinois. »
Ce n’est plus, désormais, espion contre espion. C’est espion contre Twitter, observateur d’avion, criminel, activiste, personne qui s’ennuie sur Internet, et qui sait qui d’autre encore.
Les études suggèrent généralement qu’année après année, moins de 60 pour cent du trafic web est humain ; certaines années, selon certains chercheurs, une bonne majorité du trafic est composée de bots. Le Times a rapporté cette année que durant une partie de l’année 2013, une bonne moitié du trafic sur YouTube avait été constituée de « bots se faisant passer pour des personnes », une proportion si élevée que les employés ont craint un point d’inflexion au-delà duquel les systèmes de YouTube pour détecter le trafic frauduleux commenceraient à considérer le trafic des bots comme réel et le trafic humain comme faux. Ils ont appelé cet événement hypothétique « l’Inversion ».

Ces systèmes biométriques, utilisés depuis quelques années pour contrôler, par exemple, les accès à des bâtiments sensibles, sont censés reconnaître le réseau de veines qui court sous la paume des mains ou dans les doigts. Ces dispositifs, très populaires en Asie et utilisés, ont expliqué les chercheurs, pour déverrouiller des ordinateurs, contrôler l’accès à des hôpitaux ou à des installations nucléaires, sont des alternatives aux classiques (et vulnérables) systèmes de reconnaissance des empreintes digitales. […] C’est une tradition du Chaos Communication Congress (CCC) que de montrer les limites des systèmes de sécurité biométrique, qui sont vus comme un danger pour les libertés dans la communauté des hackeurs.
Pour que les gens puissent s’engager en faveur du revenu de base universel, il faut des données, ce que de nombreux tests ont tenté d’obtenir. Mais cette année, un certain nombre d’expériences ont été interrompues, retardées ou arrêtées après un court laps de temps. Cela signifie que l’approvisionnement possible en données a également été coupé.
À partir de janvier, il y aura un nouveau moteur de recherche sur les 20.000 ordinateurs de l’université de Nantes. Fini le monopole de Google. Ils seront équipés d’un moteur de recherches 100 % français, Qwant. Si le ministère de la Défense, l’Assemblée nationale et la mairie de Paris ont déjà choisi Qwant, Nantes est la première université à le faire.

« Il y a trois sortes de violence. La première, mère de toutes les autres, est la violence institutionnelle, celle qui légalise et perpétue les dominations, les oppressions et les exploitations, celle qui écrase et lamine des millions d’hommes dans ses rouages silencieux et bien huilés. La seconde est la violence révolutionnaire, qui naît de la volonté d’abolir la première. La troisième est la violence répressive, qui a pour objet d’étouffer la seconde en se faisant l’auxiliaire et la complice de la première violence, celle qui engendre toutes les autres.
Il n’y a pas de pire hypocrisie de n’appeler violence que la seconde, en feignant d’oublier la première, qui la fait naître, et la troisième qui la tue. »Dom Helder Camara
La situation révèle que les géants de la tech non seulement ne repèrent pas les contenus offensants dans leurs propres applications, mais également dans les applications tierces qui hébergent leurs publicités et qui leur rapportent de l’argent.
Il n’a pas encore été décidé quelles entreprises construiront le nouveau portail de commerce électronique du gouvernement américain, mais on s’attend globalement à ce qu’Amazon joue un rôle dominant, ce qui lui donnera une position importante sur le marché de 53 milliards de dollars pour l’approvisionnement fédéral en produits commerciaux. Amazon est également favorite pour remporter un contrat séparé de 10 milliards de dollars avec le Pentagone, connu sous le nom de Jedi, qui permettra de transférer les données du ministère de la Défense vers un système informatique en nuage exploité commercialement. Amazon opère déjà un service cloud pour la communauté du renseignement américain, dont un contrat avec la CIA, et a déclaré qu’elle pouvait protéger les données les plus top secrètes dans un cloud isolé de l’Internet public.

Imaginez un studio de film, avec des artistes et techniciens qualifiés, qui travaillent sur des films ou des séries intéressantes… et qui les partagent sous une Licence Libre, pour être visibles par tous, partout (télé, cinéma, web…), partageables et réutilisables.
Imaginez maintenant que ce studio utilise essentiellement du Logiciel Libre (et de l’Open Hardware si disponible), qu’ils le corrigent, voire modifient et l’améliorent au besoin, aussi bien pour des logiciels finaux (tels que GIMP, Blender, Inkscape…), de bureau (tel GNOME), voire jusqu’au système d’exploitation (GNU/Linux) et tout le reste !

Le réseau cellulaire est aussi vital pour la société américaine que le réseau routier et les réseaux électriques. Les vulnérabilités de l’infrastructure de téléphonie mobile menacent non seulement la vie privée et la sécurité des personnes, mais aussi celles du pays. Selon les services de renseignements, des espions écoutent les conversations téléphoniques du président Trump et utilisent de fausses tours de téléphonie cellulaire à Washington pour intercepter les appels téléphoniques. L’infrastructure de communication cellulaire, ce système au cœur de la communication moderne, du commerce et de la gouvernance, est terriblement peu sûr. Et nous ne faisons rien pour y remédier.
De la même manière que les médias sociaux ont radicalement réduit la barrière de la distribution des discours en ligne, en donnant la chance à quiconque publie en ligne de toucher un large public, le long régime anglais de censure monarchique s’est effondré en 1641, entraînant une forte explosion des discours et idées comme des pamphlets qui se sont soudain librement déversés des presses. Il y a eu notamment un déferlement d’opinions politiques radicales de la part de groupes militant pour des réformes religieuses, la souveraineté populaire, l’extension du suffrage, la propriété commune et même de proto-droits des femmes – exposant des concepts démocratiques et des idées libérales des siècles avant que la nation elle-même devienne une démocratie libérale.
Mais, en même temps, les brochures ont également été utilisées comme un outil de propagande politique cynique pour attiser la haine raciale et sectaire, surtout dans la lutte du Parlement contre le roi. Les Irlandais ont fait l’objet d’un discours de haine particulièrement vicieux. Et les historiens suggèrent que la propagande anti-irlandaise a contribué à alimenter le déchaînement des soldats de Cromwell en Irlande pour écraser la rébellion, après avoir été alimentés d’un régime de revendications violentes dans des brochures non censurées – comme le fait que les Irlandais tuaient et mangeaient les bébés. […] Les brochures imprimées pendant la guerre civile anglaise ont également ravivé les croyances superstitieuses en matière de sorcellerie, ce qui a entraîné une recrudescence des poursuites et des meurtres pour sorcellerie, qui avaient chuté au cours des années précédentes suite à un contrôle étatique plus strict sur les comptes rendus imprimés populaires des procès en sorcellerie.
C’est une victoire pour les FAI associatifs qui se plaignent de ne pouvoir accéder en général à une offre activée bon marché comme c’est le cas avec l’ADSL et le réseau cuivre d’Orange. Faute de moyens, ils ne peuvent déployer leur propre réseau de fibre optique. Ils doivent donc impérativement louer le réseau d’un gros acteur pour proposer du FttH à leurs adhérents. Mais la plupart du temps, les prix sont prohibitifs. Au mois d’octobre dernier la Fédération FDN, qui regroupe une trentaine d’associations, avait adressé une lettre de protestation à l’Arcep et Orange à ce sujet.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés.
Il s’agit cette fois-ci de tous les récents produits de Google (ou plutôt Alphabet) qui investissent nos pratiques et nos habitudes : des pages AMP aux fournisseurs de services tiers en passant par les assistants numériques, tout est prétexte à collecte de données directement ou non.
Traduction Framalang : Côme, Fabrice, goofy, Khrys, Piup, Serici
83. Google a d’autres produits qui pourraient être adoptés par le marché et pourraient bientôt servir à la collecte de données, tels que AMP, Photos, Chromebook Assistant et Google Pay. Il faut ajouter à cela que Google est capable d’utiliser les données provenant de partenaires pour collecter les informations de l’utilisateur. La section suivante les décrit plus en détail.
84. Il existe également d’autres applications Google qui peuvent ne pas être largement utilisées. Toutefois, par souci d’exhaustivité, la collecte de données par leur intermédiaire est présentée dans la section VIIII.B de l’annexe.
85. Les Pages optimisées pour les mobiles (AMP) sont une initiative open source menée par Google pour réduire le temps de chargement des sites Web et des publicités. AMP convertit le HTML standard et le code JavaScript en une version simplifiée développée par Google1 qui stocke les pages validées dans un cache des serveurs du réseau Google pour un accès plus rapide2. AMP fournit des liens vers les pages grâce aux résultats de la recherche Google mais également via des applications tierces telles que LinkedIn et Twitter. D’après AMP : « L’ecosystème AMP compte 25 millions de domaines, plus de 100 fournisseurs de technologie et plateformes de pointe qui couvrent les secteurs de la publication de contenu, les publicités, le commerce en ligne, les petits commerces, le commerce local etc. »3
86. L’illustration 17a décrit les étapes menant à la fourniture d’une page AMP accessible via la recherche Google. Merci de noter que le fournisseur de contenu à travers AMP n’a pas besoin de fournir ses propres caches serveur, car c’est quelque chose que Google fournit pour garantir un délai optimal de livraison aux utilisateurs. Dans la mesure où le cache AMP est hébergé sur les serveurs de Google, lors d’un clic sur un lien AMP produit par la recherche Google, le nom de domaine vient du domaine google.com et non pas du domaine du fournisseur. Ceci est montré grâce aux captures prises lors d’un exemple de recherche de mots clés dans l’illustration 17b.
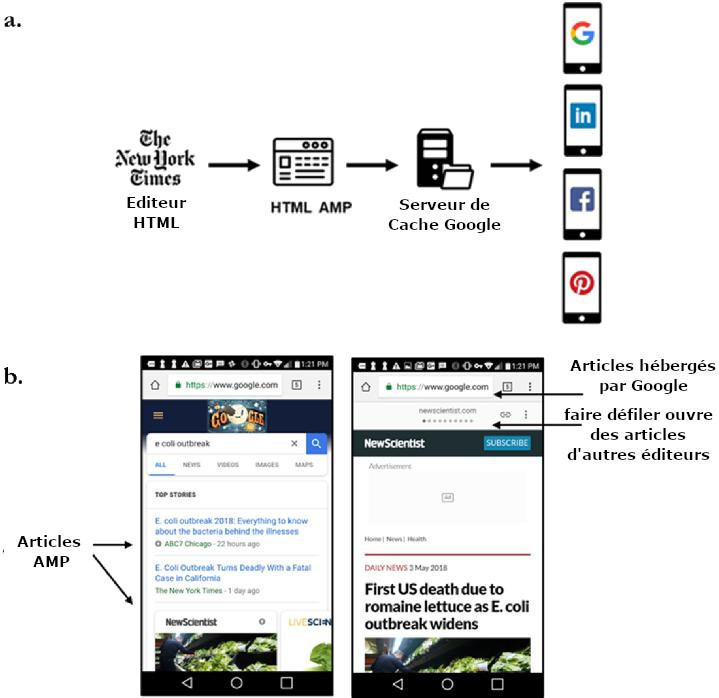
Illustration 17 : une page web normale qui devient une page AMP.
87. Les utilisateurs peuvent accéder au contenu depuis de multiples fournisseurs dont les articles apparaissent dans les résultats de recherche pendant qu’ils naviguent dans le carrousel AMP, tout en restant dans le domaine de Google. En effet, le cache AMP opère comme un réseau de distribution de contenu (RDC, ou CDN en anglais) appartenant à Google et géré par Google.
88. En créant un outil open source, complété avec un CDN, Google a attiré une large base d’utilisateurs à qui diffuser les sites mobiles et la publicité et cela constitue une quantité d’information significative (p.ex. le contenu lui-même, les pages vues, les publicités, et les informations de celui à qui ce contenu est fourni). Toutes ces informations sont disponibles pour Google parce qu’elles sont collectées sur les serveurs CDN de Google, fournissant ainsi à Google beaucoup plus de données que par tout autre moyen d’accès.
89. L’AMP est très centré sur l’utilisateur, c’est-à-dire qu’il offre aux utilisateurs une expérience de navigation beaucoup plus rapide et améliorée sans l’encombrement des fenêtres pop-up et des barres latérales. Bien que l’AMP représente un changement majeur dans la façon dont le contenu est mis en cache et transmis aux utilisateurs, la politique de confidentialité de Google associée à l’AMP est assez générale4. En particulier, Google est en mesure de recueillir des informations sur l’utilisation des pages Web (par exemple, les journaux de serveur et l’adresse IP) à partir des requêtes envoyées aux serveurs de cache AMP. De plus, les pages standards sont converties en AMP via l’utilisation des API AMP5. Google peut donc accéder à des applications ou à des sites Web (« clients API ») et utiliser toute information soumise par le biais de l’API conformément à ses politiques générales6.
90. Comme les pages Web ordinaires, les pages Web AMP pistent les données d’utilisation via Google Analytics et DoubleClick. En particulier, elles recueillent des informations sur les données de page (par exemple : domaine, chemin et titre de page), les données d’utilisateur (par exemple : ID client, fuseau horaire), les données de navigation (par exemple : ID et référence de page uniques), l’information du navigateur et les données sur les interactions et les événements7. Bien que les modes de collecte de données de Google n’aient pas changé avec l’AMP, la quantité de données recueillies a augmenté puisque les visiteurs passent 35 % plus de temps sur le contenu Web qui se charge avec Google AMP que sur les pages mobiles standard.8
91. Google Assistant est un assistant personnel virtuel auquel on accède par le biais de téléphones mobiles et d’appareils dits intelligents. C’est un assistant virtuel populaire, comme Siri d’Apple, Alexa d’Amazon et Cortana de Microsoft. 9 Google Assistant est accessible via le bouton d’accueil des appareils mobiles sous Android 6.0 ou versions ultérieures. Il est également accessible via une application dédiée sur les appareils iOS10, ainsi que par l’intermédiaire de haut-parleurs intelligents, tel Google Home, qui offre de nombreuses fonctions telles que l’envoi de textes, la recherche de courriels, le contrôle de la musique, la recherche de photos, les réponses aux questions sur la météo ou la circulation, et le contrôle des appareils domestiques intelligents11.
92. Google collecte toutes les requêtes de Google Assistant, qu’elles soient audio ou saisies au clavier. Il collecte également l’emplacement où la requête a été effectuée. L’illustration 18 montre le contenu d’une requête enregistrée par Google. Outre son utilisation via les haut-parleurs de Google Home, Google Assistant est activé sur divers autres haut-parleurs produits par des tiers (par exemple, les casques sans fil de Bose). Au total, Google Assistant est disponible sur plus de 400 millions d’appareils12. Google peut collecter des données via l’ensemble de ces appareils puisque les requêtes de l’Assistant passent par les serveurs de Google.
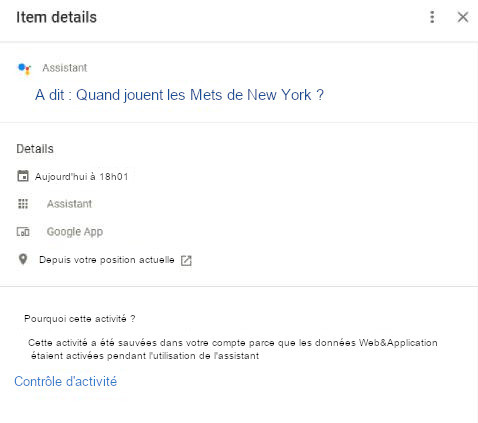
Figure 18 : Exemple de détails collectés à partir de la requête Google Assistant.
93. Google Photos est utilisé par plus de 500 millions de personnes dans le monde et stocke plus de 1,2 milliard de photos et vidéos chaque jour13. Google enregistre l’heure et les coordonnées GPS de chaque photo prise.Google télécharge des images dans le Google cloud et effectue une analyse d’images pour identifier un large éventail d’objets, tels que les modes de transport, les animaux, les logos, les points de repère, le texte et les visages14. Les capacités de détection des visages de Google permettent même de détecter les états émotionnels associés aux visages dans les photos téléchargées et stockées dans leur cloud15.
94. Google Photos effectue cette analyse d’image par défaut lors de l’utilisation du produit, mais ne fera pas de distinction entre les personnes, sauf si l’utilisateur donne l’autorisation à l’application16. Si un utilisateur autorise Google à regrouper des visages similaires, Google identifie différentes personnes à l’aide de la technologie de reconnaissance faciale et permet aux utilisateurs de partager des photos grâce à sa technologie de « regroupement de visages »1718. Des exemples des capacités de classification d’images de Google avec et sans autorisation de regroupement des visages de l’utilisateur sont présentés dans l’illustration 19. Google utilise Photos pour assembler un vaste ensemble d’informations d’identifications faciales, qui a récemment fait l’objet de poursuites judiciaires19 de la part de certains États.
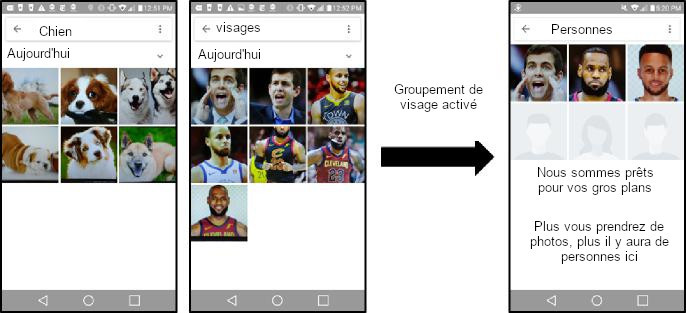
Illustration : Exemple de reconnaissance d’images dans Google Photos.
95. Chromebook est la tablette-ordinateur de Google qui fonctionne avec le système d’exploitation Chrome (Chrome OS) et permet aux utilisateurs d’accéder aux applications sur le cloud. Bien que Chromebook ne détienne qu’une très faible part du marché des PC, il connaît une croissance rapide, en particulier dans le domaine des appareils informatiques pour la catégorie K-12, où il détenait 59,8 % du marché au deuxième trimestre 201720. La collecte de données de Chromebook est similaire à celle du navigateur Google Chrome, qui est décrite dans la section II.A. Chromebooks permet également aux cookies de Google et de domaines tiers de pister l’activité de l’utilisateur, comme pour tout autre ordinateur portable ou PC.
96. De nombreuses écoles de la maternelle à la terminale utilisent des Chromebooks pour accéder aux produits Google via son service GSuite for Education. Google déclare que les données recueillies dans le cadre d’une telle utilisation ne sont pas utilisées à des fins de publicité ciblée21. Toutefois, les étudiants reçoivent des publicités s’ils utilisent des services supplémentaires (tels que YouTube ou Blogger) sur les Chromebooks fournis par leur établissement d’enseignement.
97. Google Pay est un service de paiement numérique qui permet aux utilisateurs de stocker des informations de carte de crédit, de compte bancaire et de PayPal pour effectuer des paiements en magasin, sur des sites Web ou dans des applications utilisant Google Chrome ou un appareil Android connecté22. Pay est le moyen par lequel Google collecte les adresses et numéros de téléphone vérifiés des utilisateurs, car ils sont associés aux comptes de facturation. En plus des renseignements personnels, Pay recueille également des renseignements sur la transaction, comme la date et le montant de la transaction, l’emplacement et la description du marchand, le type de paiement utilisé, la description des articles achetés, toute photo qu’un utilisateur choisit d’associer à la transaction, les noms et adresses électroniques du vendeur et de l’acheteur, la description du motif de la transaction par l’utilisateur et toute offre associée à la transaction23. Google traite ses informations comme des informations personnelles en fonction de sa politique générale de confidentialité. Par conséquent il peut utiliser ces informations sur tous ses produits et services pour fournir de la publicité très ciblée24. Les paramètres de confidentialité de Google l’autorisent par défaut à utiliser ces données collectées25.
98. Google collecte des données de tiers en plus des informations collectées directement à partir de leurs services et applications. Par exemple, en 2014, Google a annoncé qu’il commencerait à suivre les ventes dans les vrais commerces réels en achetant des données sur les transactions par carte de crédit et de débit. Ces données couvraient 70 % de toutes les opérations de crédit et de débit aux États-Unis26. Elles contenaient le nom de l’individu, ainsi que l’heure, le lieu et le montant de son achat27.
99. Les données de tiers sont également utilisées pour aider Google Pay, y compris les services de vérification, les informations résultant des transactions Google Pay chez les commerçants, les méthodes de paiement, l’identité des émetteurs de cartes, les informations concernant l’accès aux soldes du compte de paiement Google, les informations de facturation des opérateurs et transporteurs et les rapports des consommateurs28. Pour les vendeurs, Google peut obtenir des informations des organismes de crédit aux particuliers ou aux entreprises.
100. Bien que l’information des utilisateurs tiers que Google reçoit actuellement soit de portée limitée, elle a déjà attiré l’attention des autorités gouvernementales. Par exemple, la FTC a annoncé une injonction contre Google en juillet 2017 concernant la façon dont la collecte par Google de données sur les achats des consommateurs porte atteinte à la vie privée électronique29. L’injonction conteste l’affirmation de Google selon laquelle il peut protéger la vie privée des consommateurs tout au long du processus en utilisant son algorithme. Bien que d’autres mesures n’aient pas encore été prises, l’injonction de la FTC est un exemple des préoccupations du public quant à la quantité de données que Google recueille sur les consommateurs.
101. Google compte un pourcentage important de la population mondiale parmi ses clients directs, avec de multiples produits en tête de leurs marchés mondiaux et de nombreux produits qui dépassent le milliard d’utilisateurs actifs par mois. Ces produits sont en mesure de recueillir des données sur les utilisateurs au moyen d’une variété de techniques qui peuvent être difficiles à comprendre pour un utilisateur moyen. Une grande partie de la collecte de données de Google a lieu lorsque l’utilisateur n’utilise aucun de ses produits directement. L’ampleur d’une telle collecte est considérable, en particulier sur les appareils mobiles Android. Et bien que ces informations soient généralement recueillies sans identifier un utilisateur unique, Google a la possibilité d’utiliser les données recueillies auprès d’autres sources pour désanonymiser une telle collecte.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}