Khrys’presso du lundi 3 décembre
lundi 3 décembre 2018 à 07:42Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Brave New World
- Un scientifique chinois a-t-il fait naître les premiers bébés CRISPR ? (theconversation.com) – voir aussi : La manipulation génétique sur les « bébés CRISPR » a-t-elle mis en danger leur santé ? (numerama.com)
- En Chine, les Millennials utilisent des nus pour garantir leurs prêts (vice.com – en anglais)
Un certain nombre de prêteurs douteux se sont rendu compte que les jeunes acheteurs cherchent désespérément des prêts, et exigent que les clients leur remettent des selfies nus en garantie. Si les remboursements ne sont pas effectués à temps, les prêteurs menacent de les divulguer à la famille et aux amis de la personne. Bon nombre d’entre eux facturent également des intérêts sur le prêt initial, ce qui a pour effet d’endetter encore plus leurs victimes et de les obliger à envoyer davantage de photos et de vidéos.
- En Chine, votre voiture pourrait bien être en train de parler au gouvernement (apnews.com – en anglais)
Plus de 200 fabricants, dont Tesla, Volkswagen, BMW, Daimler, Ford, General Motors, Nissan, Mitsubishi et NIO, une start-up de véhicules électriques cotée aux États-Unis, transmettent des informations de position et des dizaines d’autres données aux centres de surveillance soutenus par le gouvernement. Généralement, cela se produit à l’insu des propriétaires de voitures.
- Le crédit social chinois, système de notation des citoyens, sera généralisé dès 2021 (sciencesetavenir.fr)
Pour l’heure, d’ici 2020, la Chine laisse plusieurs sociétés privées gérer leurs propres systèmes de crédit social. Avec des effets déjà cocasses : selon un article de la BBC, un système basé sur Sesame Credit (branche financière du géant Alibaba, qui utilise la notation depuis longtemps pour accorder ou non un crédit) est déjà utilisé par le plus grand site de rencontre chinois, Baihe, afin de… fournir davantage de « matchs » aux bons citoyens ! En d’autre terme, c’est la ludification (acte de rendre semblable à un jeu vidéo, grâce à un systèmes de points) de la vie sociale même qui fonde l’adhésion volontaire des citoyens à ce système panoptique de la surveillance de chacun par des algorithmes…
- Une nouvelle loi pourrait donner au Royaume-Uni un accès inconstitutionnel aux données personnelles des Américains, préviennent des groupes de défense des droits de la personne (theintercept.com – en anglais)
- D’ici 2025, près de 30 pour cent des données générées le seront en temps réel, selon IDC (zdnet.com – en anglais)
- Du spam au chantage, l’exploitation juteuse des données personnelles des journalistes (lefigaro.fr)
- Les tchats du service client vous regardent taper avant que vous appuyiez sur “enter” ; (hmmdaily.com – en anglais)
- Urban Massage a exposé une énorme base de données clients, y compris des commentaires sensibles sur les clients flippants. (techcrunch.com – en anglais)
Les dossiers comprenaient des milliers de plaintes de la part des employés au sujet de leurs clients, dont des plaintes particulières, notamment des blocages de comptes pour comportement frauduleux, des abus du système de référencement et des annulations continuelles. Mais de nombreux dossiers contenaient également des allégations d’inconduite sexuelle de la part de clients – comme la demande de « massage dans la région génitale » et la demande de « services sexuels de la part du thérapeute ». D’autres ont été marqués comme « dangereux », tandis que d’autres ont été bloqués en raison d’ « investigations policières ». Chaque plainte incluait des renseignements personnels permettant d’identifier le client, notamment son nom, son adresse, son code postal et son numéro de téléphone.
- Un piratage compromet les données de centaines de millions de clients du groupe hôtelier Marriott (lemonde.fr)
- Des escrocs modifient les coordonnées des banques sur Google Maps pour frauder les gens. (businessinsider.fr – en anglais)
- Les ordinateurs du Sénat américains vont chiffrer leurs données (zdnet.fr)

- Former Staffers Say FCC May Be Hiding Data Showing Broadband Industry Problems (motherboard.vice.com – en anglais)
- Le règlement antiterroriste détruira-t-il Signal, Telegram et ProtonMail ? (laquadrature.net)
Par ce texte, le gouvernement pourrait trouver une manière détournée de gagner un combat qu’il mène depuis longtemps et qui le frustre particulièrement : celui de la lutte contre le chiffrement de nos conversations.
Le règlement, en cours d’examen devant le Parlement européen, remettrait ainsi en cause un droit pourtant essentiel pour garantir nos libertés fondamentales face aux possibilités d’arbitraire de l’État et de la surveillance généralisée d’acteurs privés. - RGPD : 45 000 Européens ont rejoint un recours collectif contre les géants du web (numerama.com)
- Le million ! Uber prend deux amendes des CNIL britannique et néerlandaise (nextinpact.com)
- Reddit entre dans la guerre contre les articles 11 et 13 sur le droit d’auteur (newsmonkey.be)
- Quand l’Internet Archive oublie (gizmodo.com – en anglais)
Pouvoir faire confiance aux sites d’archives pour montrer la trace numérique et l’origine des contenus n’est pas seulement un outil indispensable pour les journalistes, mais c’est également utile pour tous ceux qui tentent de retrouver des pages Web en voie de disparition. Avec cela à l’esprit, le fait que l’Internet Archive ne lutte pas vraiment contre les demandes de retrait devient un problème. Ce n’est pas le seul recours : Lorsqu’un administrateur de site choisit de bloquer le crawler Wayback en utilisant un fichier robots.txt, le crawling ne s’arrête pas. Au lieu de cela, l’historique complet de la machine à remonter le temps d’un site donné est retiré de la vue du public. En d’autres termes, si vous traitez avec une certaine marque de contenu controversé et que vous voulez éviter d’avoir à rendre des comptes, il existe au moins deux façons différentes et standardisées de l’effacer de l’archive Web indépendante la plus fiable d’Internet.
Spécial Assange
- La triste et dérangeante vérité sur Julian Assange et pourquoi vous devriez vous sentir concernés (New Matilda) (legrandsoir.info)
- L’occident lâche Julian Assange (les-crises.fr)
« Dans mon pays, l’Italie, même les chefs mafieux qui ont étranglé un enfant et dissous son cadavre dans un baril d’acide passent une heure dehors. Assange ne le peut pas. »
Spécial France
- Sénat : vers une taxe sur les forfaits mobiles et Internet ? (generation-nt.com)
- Désinformation : le Sénat français va, lui aussi, demander des comptes à Facebook (lemonde.fr)

- Plus politiques que dans les journaux : les gilets jaunes dans le miroir de Facebook (arretsurimages.net)
- Ciblage publicitaire non consenti : la CNIL lève la mise en demeure de 2 entreprises françaises (numerama.com)
- Réglementation des systèmes de caisse : les logiciels libres de mieux en mieux pris en compte par Bercy (april.org)
- Vers un découpage d’EDF en trois, avec une holding et deux filiales pour isoler le nucléaire (usinenouvelle.com)
- La région Île-de-France, la SNCF, la RATP et le quartier de la Défense lancent, ce mercredi, une expérimentation pour lisser les horaires de départ et d’arrivée des salariés (leparisien.fr)
- « J’ai craqué, j’ai repris la voiture » : des usagers du train racontent ce qui les a contraints à renoncer (francetvinfo.fr)
- Une voiture autonome doit-elle épargner l’enfant ou la personne âgée ? Le choix des Français (numerama.com)
- Nantes. « Ils ne voulaient pas de Calais, ils ont fait Beyrouth » (ouest-france.fr)
- Marseille effondrée – Alèssi Dell’Umbria (lundi.am)
Spécial GAFAM
- Le projet de taxation des Gafa par l’UE toujours à la peine (sciencesetavenir.fr)
- Étude : Google est le plus grand bénéficiaire du RGPD grâce à sa position dominante, et à une concentration sur le marché de la publicité en ligne (developpez.com)
- RGPD : 7 plaintes déposées contre Google, un record (zdnet.fr)
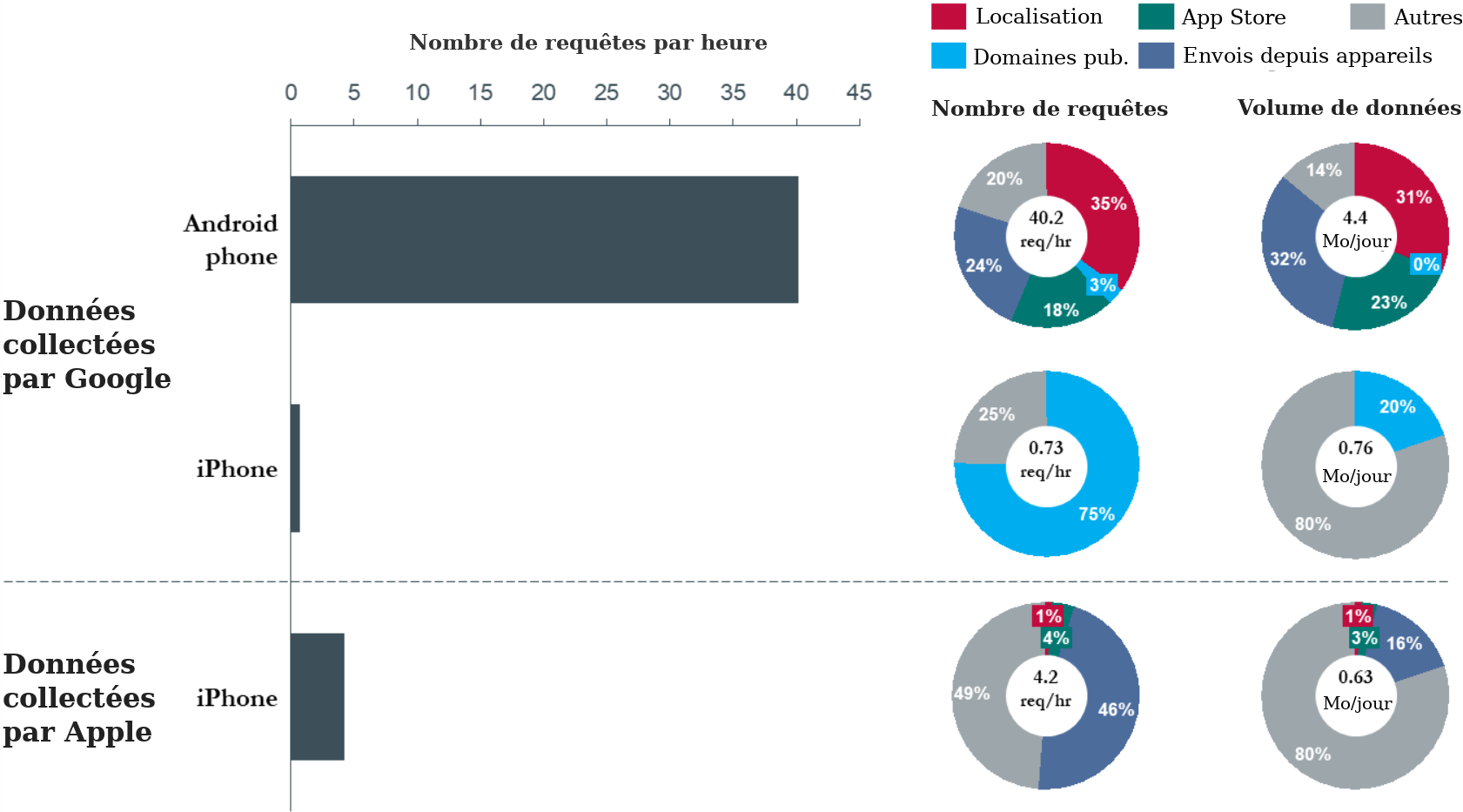
- Les données que récolte Google – Ch.3 (framablog.org)
- Comment Google passe d’un moteur de recherche à un moteur de réponses (zdnet.fr)
- L’UE s’intéresse aux pratiques de Google sur la recherche locale (sciencesetavenir.fr)
- Le Projet Fi est mort, vive Google Fi (numerama.com)
La firme de Mountain View a renommé son projet d’opérateur de réseau mobile virtuel. Dans le même temps, elle annonce une large compatibilité avec les smartphones.[…] L’initiative de Google avec Fi est la traduction concrète d’une bataille discrète, mais aux enjeux colossaux qui se joue depuis quelques années. Le secteur des télécoms est l’objet d’une rivalité croissante entre les opérateurs et les géants du numérique, les premiers voyant leurs positions de plus en plus contestées par les seconds. L’une des clés de cette bataille est l’émergence de l’eSIM.
- Les équipes de sécurité et de protection de la vie privée ont été écartées du projet secret de Google en Chine (theintercept.com – en anglais)
- 15 m3 de déchets électroniques déversés devant le siège d’Amazon (mrmondialisation.org)
- L’autorité allemande de la concurrence enquête sur Amazon (sciencesetavenir.fr)
- Amazon confirme qu’elle travaille sur un projet visant à extraire les données des dossiers des patients et à diagnostiquer plus précisément les maladies. (cnbc.com – en anglais)
- Les Démocrates demandent des informations sur l’utilisation de l’outil de reconnaissance faciale d’Amazon par les forces de l’ordre (thehill.com – en anglais)
“La technologie de reconnaissance faciale pourrait un jour être un outil utile pour les responsables du maintien de l’ordre public qui travaillent à protéger le public américain et à assurer notre sécurité. Toutefois, à l’heure actuelle, nous sommes sérieusement préoccupés par le fait que ce type de produit présente d’importants problèmes d’exactitude, impose un fardeau disproportionné aux communautés de couleur et pourrait entraver la volonté des Américains d’exercer en public leurs droits du premier amendement.”
- Amazon a « utilisé des gardes néonazis pour garder la main d’œuvre immigrée sous contrôle » en Allemagne (independent.co.uk – en anglais)
- Après avoir révolutionné l’IT avec son infrastructure et ses services de cloud computing, Amazon Web Services va t-il se pencher sur le cas des télécommunications ? (zdnet.fr) – voir aussi : AWS veut être le maître du Monde (techcrunch.com – en anglais)
- On peut maintenant acheter la mini voiture autonome d’Amazon (mais il faut la programmer) (numerama.com)

- Facebook : comment le parlement britannique a saisi des documents confidentiels par la force (numerama.com)
- Et si Facebook faisait payer l’accès aux données utilisateur ? (zdnet.fr)
- « Le problème, c’est Facebook » : les législateurs de neuf pays disent à Zuckerberg qu’il doit rendre des comptes. (techcrunch.com – en anglais)
- Ingérence russe : Facebook savait-il dès 2014 ? (zdnet.fr)
- Ce document fait partie de la recherche commissionnée par Facebook sur George Soros (buzzfeednews.com – en anglais)
- Facebook néglige ses employés et utilisateurs noirs, affirme Mark Luckie, un ex-salarié du réseau social (nouvelobs.com)
- Facebook et le MIT se servent de l’IA pour donner des adresses aux personnes qui n’en ont pas (engadget.com – en anglais)
- Microsoft détrône Apple et redevient la première capitalisation boursière (lemonde.fr)
- Windows 10 : L’office fédéral allemand pour la sécurité de l’information publie une analyse des fonctions de télémétrie (developpez.com)
- Microsoft HoloLens entre dans l’armée US (zdnet.fr)

Et cette semaine, on soutient…
- Illyse : Nous avons besoin de vous pour proposer de la fibre optique dans la Loire ! (helloasso.com)
- Procédure contre le renseignement français devant les juges de l’UE : aidez-nous à finaliser ! (laquadrature.net)
Les lectures de la semaine
- « J’aime quand un plan se déroule sans accroc ». Mark Zuckerberg en cour d’appel (affordance.info)
En l’état rien ne permettra de limiter significativement le potentiel de nuisance de Facebook et de son architecture technique toxique. Rien parce qu’aucun algorithme jamais ne pourra défendre la démocratie. Rien parce le principal problème de Facebook est extraordinairement simple : il vient essentiellement de son modèle économique et on ne change pas un modèle économique qui rapporte, si toxique et destructeur soit-il.
Donc comme Facebook ne changera pas de modèle économique, comme Facebook continuera de déployer son architecture technique toxique sur des pans de plus en plus essentiels de nos vies et de nos démocraties, comme aucune intelligence artificielle ne permettra jamais de solutionner le problème de l’insondable bêtise de nos comportements grégaires dans des contextes particuliers de communication (numérique ou non), il faut, oui j’en suis convaincu, nationaliser Facebook. Ou le démanteler. Ce qui revient au même.
C’est important et c’est urgent.
Parce qu’il est important et urgent que l’essentiel de ces interactions numériques, de nos interactions numériques, reviennent dans l’espace public. Qu’elles y soient re-situées pour pouvoir mieux y être restituées. Et que s’y appliquent, aussi simplement qu’essentiellement et exclusivement, les seules lois régulant l’espace public de la démocratie.
Tout le reste, c’est de la comm. et des « Relations Publiques ». Compris ? - Gafams : et si la révolution venait de l’intérieur ? (internetactu.net)
- Quitter hotmail… | FAImaison (faimaison.net – article de février 2018)
Si vous possédez une adresse de courrier électronique @hotmail.fr, @hotmail.com, @outlook.com, etc. sachez que certains internautes ne peuvent pas vous envoyer de mails. Pourquoi ? Parce que Microsoft, l’entreprise qui gère votre boite mail, refuse les mails provenant de « petits » réseaux par peur du spam. […] Internet a été conçu pour être un réseau décentralisé. C’est une de ses forces et une des raisons de la diversité de ses contenus. Les « règles de circulation » sur Internet sont donc pensées pour permettre cette diversité d’acteurs. Malheureusement, aujourd’hui quelques grosses multinationales (les GAFAM notamment) gèrent une partie significative des services en ligne, il y a donc un risque pour que ces grosses entreprises tentent d’imposer leurs propres règles au détriment des petits. Le cas de Microsoft qui refuse les mails provenant de petits réseaux en est une illustration parfaite : en durcissant ses règles de tri du spam depuis une position de pouvoir (nombreuses boites mail gérées), Microsoft tente de faire passer en force des règles qui ne font pas consensus.
- Accros aux smartphones : six lanceurs d’alerte à écouter de toute urgence (telerama.fr)
- Effets de la technologie sur notre cerveau : la grande inconnue (usbeketrica.com)
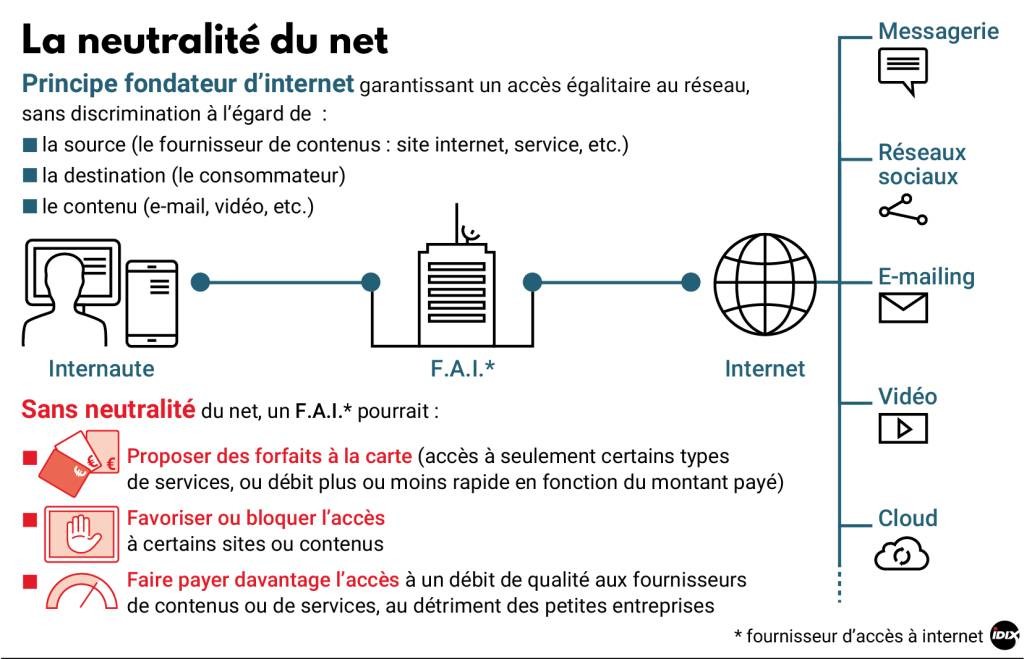
- Ce que peut faire votre Fournisseur d’Accès à l’Internet (framablog.org)
- Pourquoi l’intelligence artificielle risque de continuer à tuer (theconversation.com)
Dans l’exemple des voitures autonomes, l’utilisation aveugle de DNN couplés directement à des systèmes de contrôle des actions du véhicule serait très risquée : ce serait équivalent à demander à un chauffeur de taxi qui a perdu plus de 80 % de son cerveau suite à un accident (et ne conservant que cette voie occipito-temporale) de conduire une voiture. Il n’est tout simplement pas possible de demander à ces systèmes plus que ce pour quoi ils ont été conçus à l’origine au risque de produire des accidents dramatiques.[…] L’utilisation aveugle de DNN (ou d’autres systèmes artificiels) sans retour, ni comparaison à la neuro-inspiration pour des fonctions cognitives différentes n’est pas seulement limité en performance, c’est tout simplement dangereux […] il nous semble primordial de comprendre comment le cerveau réalise d’autres fonctions cognitives (contrôle moteur, intégration multi-sensorielle, etc.) afin de les comparer aux techniques d’ingénierie actuelles réalisant ces fonctions dans l’optique de produire des IA plus sûres et plus efficaces.
- Le spectre du contrôle : une théorie sociale de la ville intelligente ; (firstmonday.org – en anglais ; date de 2015)
- Sole and Despotic Dominion : Fiction (par Cory Doctorow) (reason.com – en anglais)
- #BienvenueEnFrance (affordance.info)
- « Gilets jaunes » : et maintenant ? (usbeketrica.com)
- Kate Raworth : « Nous devons briser notre dépendance à la croissance » (la théorie du Donut) (usbeketrica.com)
- Pour lutter contre le changement climatique, inspirons-nous de Linux ! (theconversation.com)
Les BDs/graphiques/photos de la semaine
- Infographie : les données que les grandes entreprises de la Tech ont sur vous (ou, du moins, celles qu’elles admettent avoir) (securitybaron.com – en anglais)
- Traquer le client jusque dans les chiottes
- Tor, pour préserver l’intimité de ses proches
- Projet de règlement anti-terroriste : une nouvelle attaque contre le chiffrement ?
- ArchLinux
- Enfermé dans son corps de métal
- Petits métiers oubliés
- Marketing & sales
- LVMH
- De Jupiter à Gulliver
- Gilets jaunes
- La violence des casseurs
- Qui sont les casseurs ?
- La recette des totalitarismes
- La vérité sur le Père Noël
Les vidéos/podcasts de la semaine
- YunoHost : vers l’auto-hébergement et au-delà (videos-libr.es – pour la nouvelle version de la conf au Capitole du Libre, uniquement un lien YouTube pour l’instant…)
- Internet, un grand pouvoir implique de grandes libertés – Geek Faëries 2018 (peertube.mindpalace.io)
- Notre Internet, nos câbles (video.lqdn.fr)
- L’avenir d’Amazon Echo et de Google Home s’annonce effrayant (zdnet.fr ; lien direct vers la vidéo sur vimeo.com : BIG DATA – « L1ZY »)
- Capitalisme : victoire par chaos climatique – #DATAGUEULE 83 (peertube.datagueule.tv)
- videosdulib.re, une instance PeerTube pour des vidéos en rapport avec le libre
- peertube.librelois.fr, une instance PeerTube parlant en particulier de monnaie libre
Les autres trucs chouettes de la semaine
- À quoi s’attendre de Linux en 2019 (networkworld.com – en anglais)
- Les services du Fédiverse fin 2018 (lord.re)
- Scratch3 est téléchargeable pour une utilisation hors-ligne grâce à l’académie de Grenoble (ac-grenoble.fr) cf aussi Scratch 3.0 (fr.scratch-wiki.info)
- Mozilla : Retour du Calendrier de l’Avent Extensions (blog.mozfr.org)
- Calendier de l’avent Geek (luc-damas.fr – pour les pressé·e·s, lien direct vers le calendrier)
- Covoiturage Libre devient une coopérative pour concurrencer BlaBlaCar (wedemain.fr) – voir aussi : Mobicoop, l’alternative à Blablacar (la-croix.com) et Numérique. La coopérative de covoiturage Mobicoop à l’assaut de Blablacar (humanite.fr)

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
Avec un gros merci à Goofy pour ses toujours chouettes illustrations ! ! !









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}